





-
在炼铁过程中,密切监测和控制高炉的运行,直接关系到生产的安全和效率,是至关重要的。其中一个关键的性能指标是铁水温度,由于各种挑战,铁水温度难以预测和控制。挑战包括:1)高炉具有复杂的非线性过程动力学。由于炉料顶降、化学反应、炉缸热质量大等原因,该工艺本身具有较大的时间延迟;2)由于技术限制、操作条件恶劣等诸多原因,并非所有过程传感器都是可靠的,导致数据缺失、异常值等数据质量较差。如果不充分考虑这些因素,操作人员就无法掌握对高炉运行的完全控制,往往会对炉膛内部状态产生误解,决策失误,导致铁水温度变化较大。
应对这些挑战最有希望的方法是利用人工智能(AI)和机器学习(ML)模型。有几项研究,证明ML/AI模型可以提高高炉运行的稳定性和效率,主要原因是减少了处理复杂动态数据的人力。这些研究中常用的ML/AI算法是集成决策树(如增强树、随机森林)和深度学习(如LSTM)。
这项工作的目的是应用ML/AI方法来协助高炉操作人员系统地、一致地评估炉热状态,监测异常操作情况,并实时控制炉燃料率和生产率,以实现高炉稳定和经济地运行。
2
建模方法
图1描述了建模方法的主要步骤,包括:数据预处理、离群值过滤、堆叠ML建模、模型评估和调优。以下将详细描述各步骤。

2.1 数据预处理
本研究使用的数据集来自一个日产量为6000吨的运行高炉。数据周期为2个月,包含大约700个铸件。每5分钟采样一次工艺数据,然后由每个铸件汇总,以同步连续工艺变量和批量操作,如炉料、铁水和炉渣样品分析。
在这个数据集中,响应变量是高炉的热状态。连续测量铁水温度,并假设每次浇注过程中连续测量的最大值代表炉内温度。然后基于某些阈值用这个温度来确定炉子的状态,即热态、正常、或冷态。
数据集中有三种类型的预测变量:1)直接从传感器测量的过程变量;2) 实验室变量,如从实验室分析中获得的铁水和炉渣化学成分;3)根据炉体质量和能量平衡,计算出相应的变量。表1总结了一些关键变量。请注意,由于实验室分析的时间延迟,实验室变量是基于先前的浇铸。此外,还引入了焦矿比、天然气注入量、冷风湿度等额外滞后变量,以应对工艺延迟。

2.2 离群值过滤
工业数据集总是包含一些缺失数据和异常值,这需要对其进行检测和删除以提高模型性能。在本研究中,主成分分析(PCA)应用于这一目的。PCA是一种强大的降维技术。它简化了高维、多变量数据集的复杂性,通过将数据转换到更低的维度,使得新创建的变量(称为主成分(Principal Components, PC))显示出最大的过程方差。每个数据点被转换到一个由PC定义的新空间,称为分数。
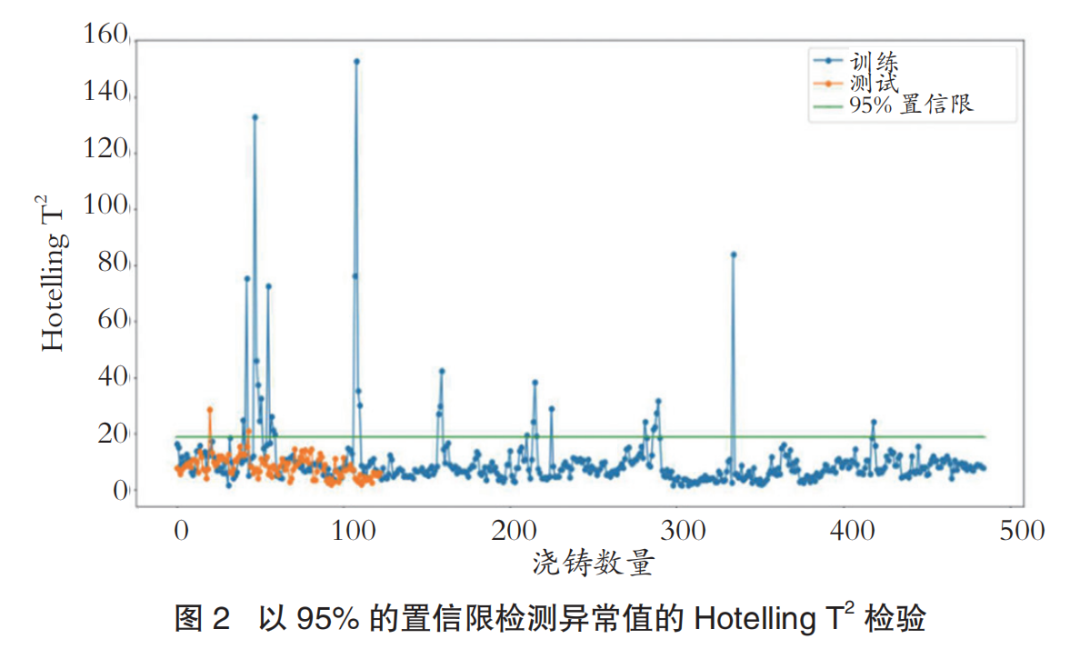
Hotelling T2是一个由PC分数和方差导出的数量,是一个从中心到变换空间中数据点投影的度量距离。它用于评估一个数据点是否偏离了大多数建模数据集。如图2所示,当Hotelling T2高于95%置信限时,数据点可以被认为是偏离的,因此是一个异常值。
2.3 堆叠机器学习模型
将两种机器学习算法串联堆叠起来,建立高炉热状态预测模型。该模型支持向量回归接受2.1节中讨论的所有变量并返回铁水温度预测。然后利用预测温度来创建两个新特征——预测热类和预测偏差变量。然后,XGBoost (梯度提升树)算法将这些新的特征与所有其他变量一起用于炉膛热状态分类。试验证明,这种叠加机制显著提高了热态预测的准确率。
2.4 模型性能评估
为评估模型性能,数据集被分成训练集和测试集,比例为80%和20%。表2给出了3级分类模型的混淆矩阵,其中:
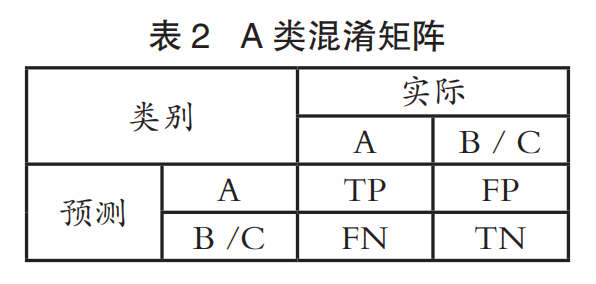
真阳性(TP):模型正确预测了目标(阳性)类别(例如:实际类是冷的,预测类也是冷的)。
真阴性(TN):模型正确预测非目标(阴性)类别(例如,实际类不冷,预测类也不冷)。
假阳性(FP):模型错误预测了目标(阳性)类别(例如,实际类不冷,而预测类是冷的)。
假阴性(FN):模型错误预测了非目标(阴性)类别(例如,实际类是冷的,而预测类不是冷的)。
使用两个分类模型评价指标来量化性能:F值和准确率,定义如式(1)-式(4),其中n为TP、FP、FN或TN每一类的测试结果个数。

3
建模结果
表3总结了使用非堆叠和堆叠模型计算的F值和准确率。结果表明,采用堆叠机制后,整体准确率提高了6%,冷预测F值显著提高(提高了41%)。
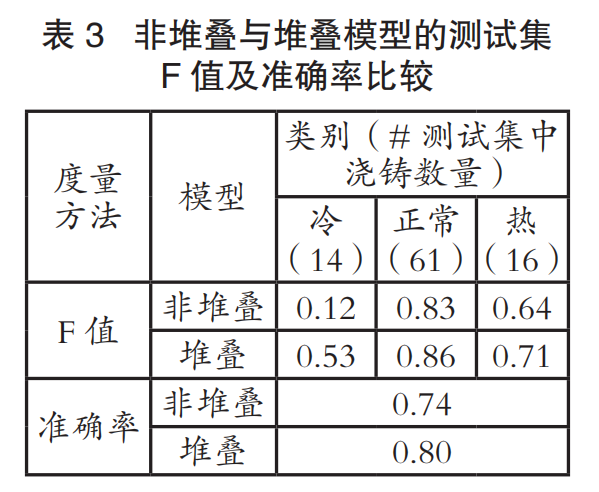
图3显示了堆叠建模案例对应铸号下的实际温度的分类模型预测结果。结果表明,大部分早期热态和后期冷态被捕获。与预测正常情况相比,预测寒冷和炎热情况的性能相对较低,可能是由于数据集中异常情况样本的比例较低。这可以通过在未来的工作中增加列车集的大小来改善。
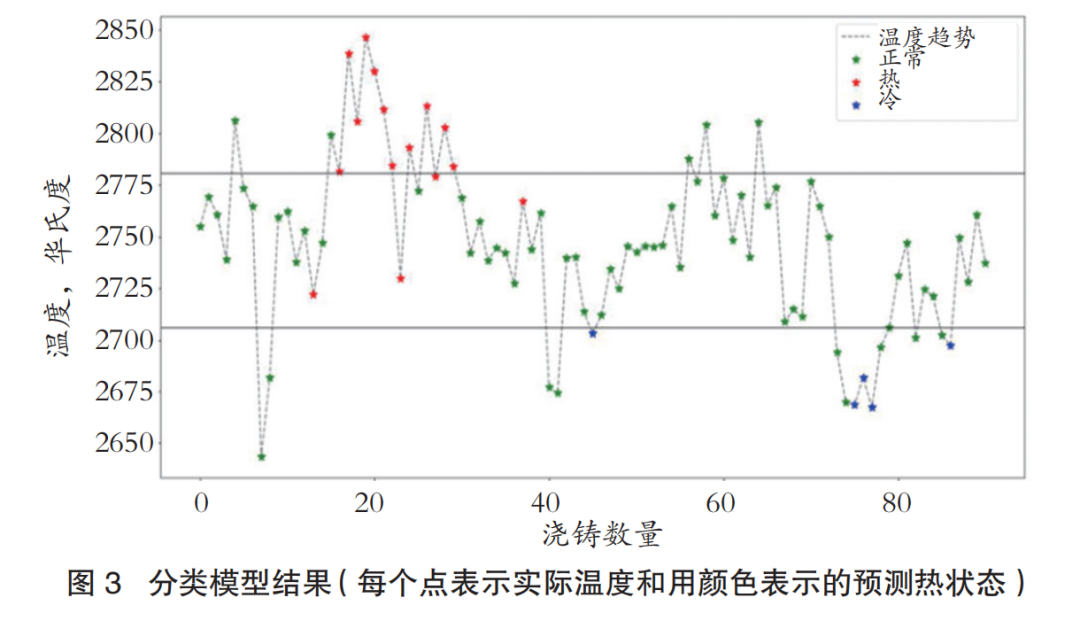
该建模结果显示了将ML模型应用于高炉操作并帮助操作人员更好地评估热状况的潜在机会。根据预测的浇铸热状态,操作人员将能够提前调整燃料速率以保持预期的热状态。
4
数字孪生的实现
数字孪生是使用领先的数字技术(如物联网(IoT)、云基础设施和ML/AI工具)对物理资产或系统的动态表示。数字孪生通过实时优化资产和/或流程,为工业环境带来了巨大的好处。Hatch公司最近一直在大力开发针对炼铁过程的数字孪生,称为高炉4.0。它允许通过实时过程监控、场景分析和操作指导来实现智能运营。最近的一个实例是高炉炉膛液位预测和浇铸指导模型。本研究开发的模型已在高炉4.0平台上作为试点实施。
试验web应用程序的用户界面由三个关键功能组成:1)异常值检测和贡献变量:使用Hotelling T2,识别异常值和对异常值的关键贡献变量。顶部中间部分显示了前5个异常值贡献者及其相对于PCA模型平均值的实时值。2)炉热状态预测:预测结果以实时更新的图形显示。类似于图3中使用的颜色代码。web应用程序在图的底部以红色、绿色和蓝色条显示预测的热状态,以及相关的测量温度值。3)通知与用户通信:当检测到异常值或预测下一播热状态异常时,将发送警报信息并显示在通知中心,通知操作人员。对于每条警报消息,操作员可以确认或拒绝预测结果并给出原因。这些信息将被记录下来,并用于将来的数据分析和模型改进。
5
结论
作为高炉4.0智能运营的一部分,这项工作的启动是为了使操作员能够对高炉的热状况进行系统评估和控制决策。该项目表明,使用基于PCA的高级离群值滤波和堆叠机器学习建模,热状态预测可以达到至少80%的准确率。
(责任编辑:zgltw)
